☰
◀ Previous △ Index Next ▶
[Run:Data]
The Data Merging view permits the user to merge the output files
generated by FLUKA into the files that will be subsequently used for
plotting or inspection of the results. Flair makes this process
transparent to the user with the Process Data page.
 One would expect that the simulation is equivalent to a counting
experiment, therefore the data will follow a Poisson distribution and the
error will be the square root of the number of events collected. This is
true provided that no biasing is used in the simulation. When importance
scoring is involved (quite typical and recommended way of working) to
calculate correctly the statistical error, apart from the final value one
has to record also the square of events/hits for every value needed. This
doubles the memory and increases the complexity for special estimators.
Therefore, FLUKA is making use of the Central Limit Theorem for
calculating the mean value of a quantity scored and the error on the
determination of the mean. The theorem states:
"The distribution of an average tends to be Normal, even when the
distribution from which the average is computed is decidedly
non-Normal."
This is the main reason we have to perform several cycles, minimum 5 is
recommended to simulate correctly a Normal distribution, and then sum-up
and average the results. In FLUKA this is done automatically with the
us?suw utilities, Where ? can be:
b=USRBIN
r=RESNUCLEi
t=USRTRACK or USRCOLL
x=USRBDX
y=USRYIELD
These programs expect as input a list of binary files generated from
FLUKA with the respective card and using as unit a negative number, and
in the end they generate a set of output files both binary, text and
tabulated with the results.
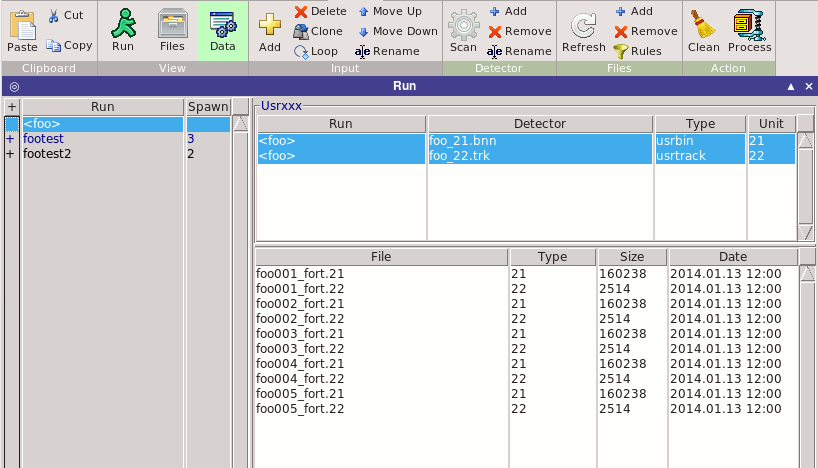
On the right side the window contains two list boxes
Top: the list of detectors (scoring units Usrxxx) requested for each run.
Automatically a default name will be assigned in the form of
"input-name"_"card"_"unit". The user with the buttons on the right
can delete the file, create a new one or rename it.
The default rule for generating the files can be configured
in the Preferences F6 dialog under the Data section
Bottom: the list of files associated with each detector
Ribbon
~~~~~~
Detector Shortcut description
----------- -------- ------------------------------------------
Scan Scan input for possible detector cards.
Warning: Only the BINARY ones will appear
ASCII files cannot be merged
Add Ins Add a detector file for processing
Remove Del Remove a detector file from processing
Rename F2 Change the name of a detector
Files Shortcut description
----------- -------- ------------------------------------------
Refresh Ctrl-R Re-scan the directory for new files
Add Ins Manually include file(s) to the processing list
Delete Del Remove selected file(s) from the processing list
Rules Open the filter dialog modify the rules of
inclusion of data files. (see below)
Action Shortcut description
----------- -------- ------------------------------------------
Clean Delete all generated detector files
Process Ctrl-Enter By pressing the Process button flair will run the
appropriate FLUKA utilities to merge the selected data
files from the Usrxx listbox. A dialog will confirm the
outcome of the operation.
Note
~~~~
The FLUKA utilities usually generate more than one output files.
Typically the merge binary data file has the requested name while for a
text file is generated with the extension _sum.lis, and a tabulated one
with the extension _tab.lis
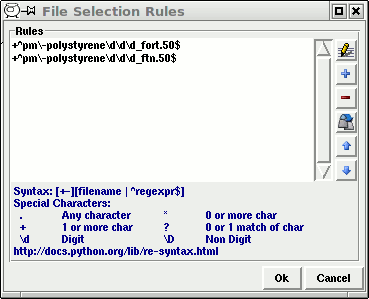
File Selection Rules
~~~~~~~~~~~~~~~~~~~~
The File Selection Rules dialog permits to user to modify the automatic
selection criteria of the files for each output. The dialog gives the
possibility to dynamically include or remove files from the processing
list, by using a set of patterns. For the moment the dialog is low level
and requires some knowledge of regular expressions. Flair automatically
adds two default rules for each scoring file.
One would expect that the simulation is equivalent to a counting
experiment, therefore the data will follow a Poisson distribution and the
error will be the square root of the number of events collected. This is
true provided that no biasing is used in the simulation. When importance
scoring is involved (quite typical and recommended way of working) to
calculate correctly the statistical error, apart from the final value one
has to record also the square of events/hits for every value needed. This
doubles the memory and increases the complexity for special estimators.
Therefore, FLUKA is making use of the Central Limit Theorem for
calculating the mean value of a quantity scored and the error on the
determination of the mean. The theorem states:
"The distribution of an average tends to be Normal, even when the
distribution from which the average is computed is decidedly
non-Normal."
This is the main reason we have to perform several cycles, minimum 5 is
recommended to simulate correctly a Normal distribution, and then sum-up
and average the results. In FLUKA this is done automatically with the
us?suw utilities, Where ? can be:
b=USRBIN
r=RESNUCLEi
t=USRTRACK or USRCOLL
x=USRBDX
y=USRYIELD
These programs expect as input a list of binary files generated from
FLUKA with the respective card and using as unit a negative number, and
in the end they generate a set of output files both binary, text and
tabulated with the results.
On the right side the window contains two list boxes
Top: the list of detectors (scoring units Usrxxx) requested for each run.
Automatically a default name will be assigned in the form of
"input-name"_"card"_"unit". The user with the buttons on the right
can delete the file, create a new one or rename it.
The default rule for generating the files can be configured
in the Preferences F6 dialog under the Data section
Bottom: the list of files associated with each detector
Ribbon
~~~~~~
Detector Shortcut description
----------- -------- ------------------------------------------
Scan Scan input for possible detector cards.
Warning: Only the BINARY ones will appear
ASCII files cannot be merged
Add Ins Add a detector file for processing
Remove Del Remove a detector file from processing
Rename F2 Change the name of a detector
Files Shortcut description
----------- -------- ------------------------------------------
Refresh Ctrl-R Re-scan the directory for new files
Add Ins Manually include file(s) to the processing list
Delete Del Remove selected file(s) from the processing list
Rules Open the filter dialog modify the rules of
inclusion of data files. (see below)
Action Shortcut description
----------- -------- ------------------------------------------
Clean Delete all generated detector files
Process Ctrl-Enter By pressing the Process button flair will run the
appropriate FLUKA utilities to merge the selected data
files from the Usrxx listbox. A dialog will confirm the
outcome of the operation.
Note
~~~~
The FLUKA utilities usually generate more than one output files.
Typically the merge binary data file has the requested name while for a
text file is generated with the extension _sum.lis, and a tabulated one
with the extension _tab.lis
File Selection Rules
~~~~~~~~~~~~~~~~~~~~
The File Selection Rules dialog permits to user to modify the automatic
selection criteria of the files for each output. The dialog gives the
possibility to dynamically include or remove files from the processing
list, by using a set of patterns. For the moment the dialog is low level
and requires some knowledge of regular expressions. Flair automatically
adds two default rules for each scoring file.
 The rules in the dialog are executed sequentially until a match is
successful.
Rules syntax
~~~~~~~~~~~~
First character defines the action. It accepts:
+ include a file
- remove a file
The rest corresponds to the regular expression that will be checked
for match against the file.
Some of the most important special characters are:
^ beginning of the string
$ end of the string
. match any character
? repeat previous match zero or one time
+ repeat previous match one or more times
* repeat previous match zero or more times
\d digit 0-9
\D everything but a digit
else any other character is matched literally
For a complete reference please see the python regular expressions
http://docs.python.org/lib/re-syntax.html
The rules in the dialog are executed sequentially until a match is
successful.
Rules syntax
~~~~~~~~~~~~
First character defines the action. It accepts:
+ include a file
- remove a file
The rest corresponds to the regular expression that will be checked
for match against the file.
Some of the most important special characters are:
^ beginning of the string
$ end of the string
. match any character
? repeat previous match zero or one time
+ repeat previous match one or more times
* repeat previous match zero or more times
\d digit 0-9
\D everything but a digit
else any other character is matched literally
For a complete reference please see the python regular expressions
http://docs.python.org/lib/re-syntax.html
◀ Previous △ Index Next ▶
 flair
flair